When and Why Do Uncertainty Quantification Methods for LLMs Work?
Why do Uncertainty Quantification methods matter?
Large Language Models (LLMs), such as GPT, LLaMA, and Phi, can produce impressive, human-like responses on a wide variety of tasks—from answering trivia questions to writing Python code (Dubey et al. 2024). Despite their impressive capabilities, these models may produce incorrect answers while maintaining high confidence and sounding plausible - an issue often referred to as hallucinations (Huang et al. 2023).
To safely rely on LLM outputs, we must understand how certain the model is about its answers. This is precisely the goal of Uncertainty Quantification (UQ) methods, which measure how much we can trust a model’s predictions.
Although numerous uncertainty quantification methods exist, it’s still unclear whether they generalize well across different contexts or data types. Recent studies, such as those exploring “multicalibration,” suggest that calibration performance can vary significantly across domains (Detommaso et al. 2024).
In particular, easy-to-use methods like Verbalized Confidence, where a model explicitly states its certainty (e.g., “I’m 80% sure”), might seem appealing but could be unreliable or overly confident in some contexts. This work aims to systematically assess when and why these discrepancies occur, providing insights into the practical use of uncertainty quantification methods.
This blog post explores why and when certain UQ methods succeed or fail. Gaining this understanding is crucial not only for building safer AI systems but also for deepening our knowledge of how these powerful models behave and when we can trust them. Furthermore, it explores how Test Time Compute techniques (Snell et al. 2024) - that is methods that rely on longer model inference via extensive sampling or reasoning - impact models confidence assessment, providing valuable insights about these upcoming methods.

Why Care about Calibration?
Effective uncertainty quantification relies heavily on calibration—a model’s predicted confidence should closely reflect its actual probability of correctness (Guo et al. 2017). Ideally, a perfectly calibrated model that claims to be “90% confident” about its answers should indeed be correct in approximately 90% of those cases. Unfortunately, most large language models, particularly those tuned using reinforcement learning with human feedback (RLHF), tend to be overly confident even when they’re incorrect (Tian et al. 2023; Kadavath et al. 2022).
Reliable calibration becomes especially critical in high-stakes domains such as medicine or finance, where trusting an incorrect but confidently presented answer can lead to serious consequences.
When assessing calibration in large language models, we identify two potential challanges:
-
Domain-Specific Calibration: Existing research indicates that a language model may be well-calibrated within one domain or dataset but poorly calibrated in another—a phenomenon known as multicalibration (Detommaso et al. 2024). This variability means confidence scores could be highly accurate for certain types of questions but unreliable for others.
-
Inconsistent Confidence Measures: There are multiple ways to extract confidence scores from LLMs, some of them described in the next section. We hypothesize that model might be accurately calibrated using one method (for example, explicitly asking the model for its confidence), yet poorly calibrated when assessed using a different approach (such as token-level probability scores). For instance, a model might provide reasonable confidence ratings verbally but have token probabilities that don’t correlate well with actual correctness.
These two possible issues may complicate the reliable adoption and use of uncertainty quantification methods. Our work aims to clarify when and why particular methods are effective, ultimately helping practitioners choose appropriate strategies for different contexts and understand models better.
How to quantify LLM’s confidence?
Several methods exist for quantifying the uncertainty of LLM-generated answers:
-
Token-Level Probabilities:
Using the raw probabilities of individual tokens as indicators of model confidence (Dhuliawala et al. 2022). -
Semantic Consistency:
Generating multiple answers with slight variations (using higher randomness, i.e., higher temperature) and measuring agreement among the answers (Farquhar et al. 2024). We can measure probability of generating given output (Semantic Probability) or entropy among the answers (Semantic Entropy). -
True/False Scoring:
Asking the model separately if its answer is true or false, then taking the probability of the model answering “True” as its confidence (Detommaso et al. 2024). -
Verbalized Confidence:
A more user-friendly method where the model explicitly states its confidence as a percentage (e.g., “I’m 85% confident in this answer.”) (Xiong et al. 2024; Yang et al. 2024). We distinguish between Verbalized Score where we ask the model to assess the correctness of generated response, and Verbalized Self Score, where the model gives confidence estimate as part of the response.
Understanding Verbalized Confidence in Detail
Verbalized confidence methods prompt the LLM to directly communicate how certain it is, typically as a percentage (0%–100%). This approach is particularly appealing because:
- It provides intuitive, human-readable uncertainty estimates.
- It’s compatible with closed-source or API-based LLMs (like OpenAI’s GPT-4), which often limit access to internal model probabilities (Xiong et al. 2024; Ni et al. 2024).
- It allows flexible prompting strategies, such as asking the model to first produce an answer and then reflect on its correctness (self-judge calibration) or asking it directly how confident it is about the given answer (judge calibration) (Yang et al. 2024; Wei et al. 2024).
However, despite these benefits, verbalized confidence estimates have notable drawbacks:
- Overconfidence: Models frequently report overly optimistic confidence levels, especially after RLHF, often claiming high certainty even when they are incorrect (Zhang et al. 2024; Yang et al. 2024; Wei et al. 2024).
- Inconsistency: Small changes in the prompt wording or context can lead to drastically different confidence estimates (Pawitan et al. 2024).
- Model Size & Reasoning Dependence: Larger models or longer reasoning times generally improves calibration, making verbalized score less useful for smaller LLMs (Jurayj et al. 2025; Xiong et al. 2024).
In fact, prior studies have found that while verbalized confidence is convenient, probabilistic methods like semantic consistency or token-level scores often outperform it in reliability (Ni et al. 2024; Wei et al. 2024). Understanding when verbalized confidence works and when it fails remains an important open research question, that could shed a light on the internal workings of LLM’s reported confidence.
Open Questions
Given these complexities, our research seeks to answer the following questions:
- RQ1: Do different UQ methods (e.g., verbalized vs. semantic) generally agree, or do they often diverge significantly?
- RQ2: Which types of questions or domains allow LLMs to accurately verbalize their uncertainty?
- RQ3: What underlying factors lead to accurate (or inaccurate) uncertainty estimates within specific domains?
- RQ4: Does extended reasoning or chain-of-thought improve the reliability of verbalized confidence?
Experimental Setup
To explore these questions, we’re planning experiments using popular question-answering datasets like TriviaQA (Joshi et al. 2017), MMLU (Hendrycks et al. 2021), and SimpleQA (Wei et al. 2024), enriched with domain-specific tags (sports, culture, reasoning complexity). We will use Llama3.1-8b-instruct and Gemma2 for UQ methods investigation across question types, and Deepseek R1 32B for experiments that require reasoning.
We’ll perform:
- Comparisons of UQ methods across domains (sports, science, etc.) to see if some methods consistently outperform others.
- Analysis of reasoning length, comparing verbalized confidence with and without chain-of-thought prompting (Wei et al. 2024).
- Assessment of domain familiarity, investigating whether familiar topics produce better calibrated confidence scores.
Through these experiments, we aim to deliver actionable insights into which uncertainty methods work best in different scenarios.
UQ Methods Effectiveness Across Question Types (February 2025)
Effective uncertainty quantification (UQ) methods should reliably distinguish correct from incorrect responses across a variety of domains and question types. In our study, we labeled a QA dataset with domain and complexity tags (e.g., history, ethics, commonsense)—partly automated via GPT-4o-mini—and then evaluated multiple UQ approaches on each category. We measured performance by treating UQ scores as inputs to a binary classification task (correct vs. incorrect answers) and calculating the ROC AUC.
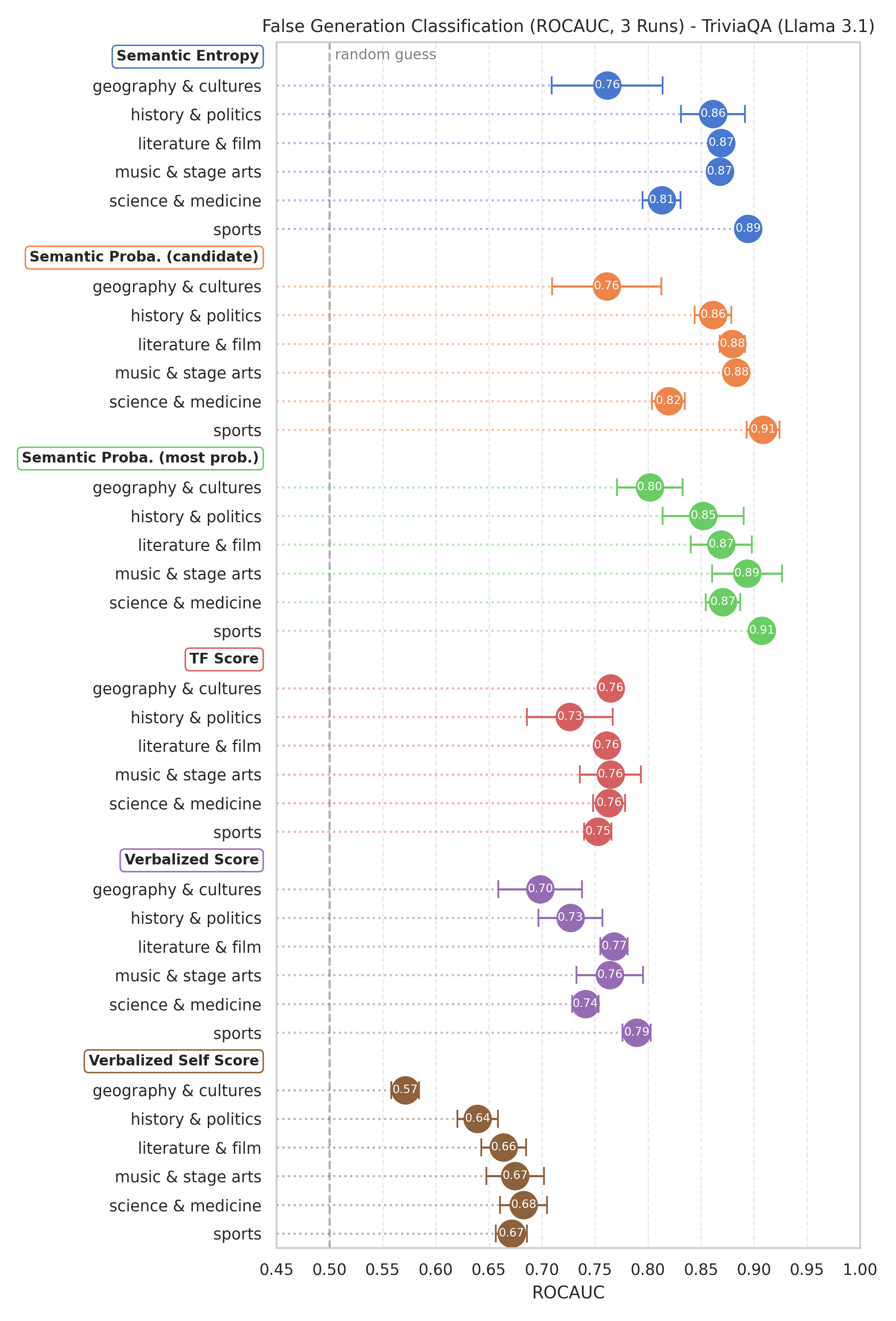
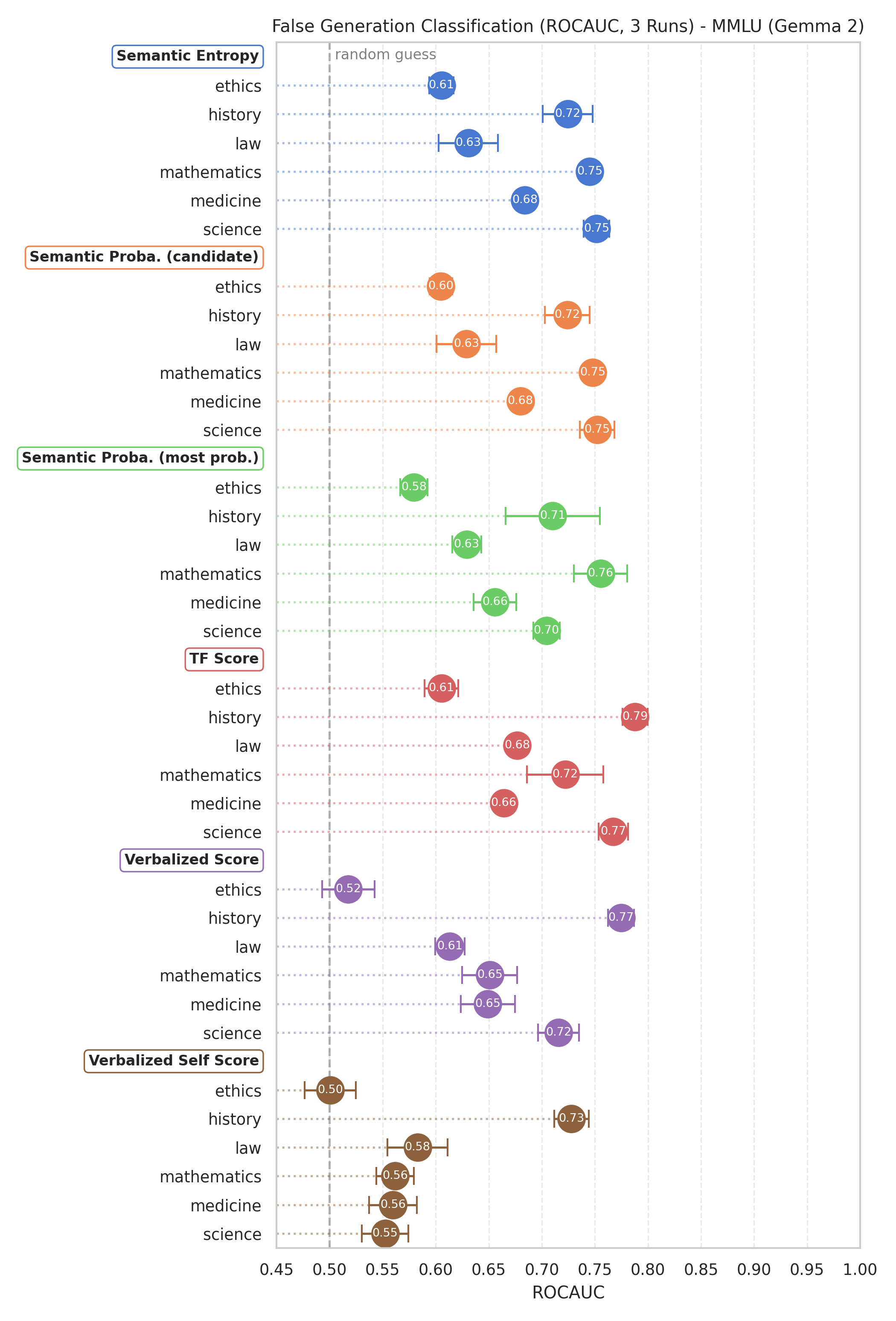
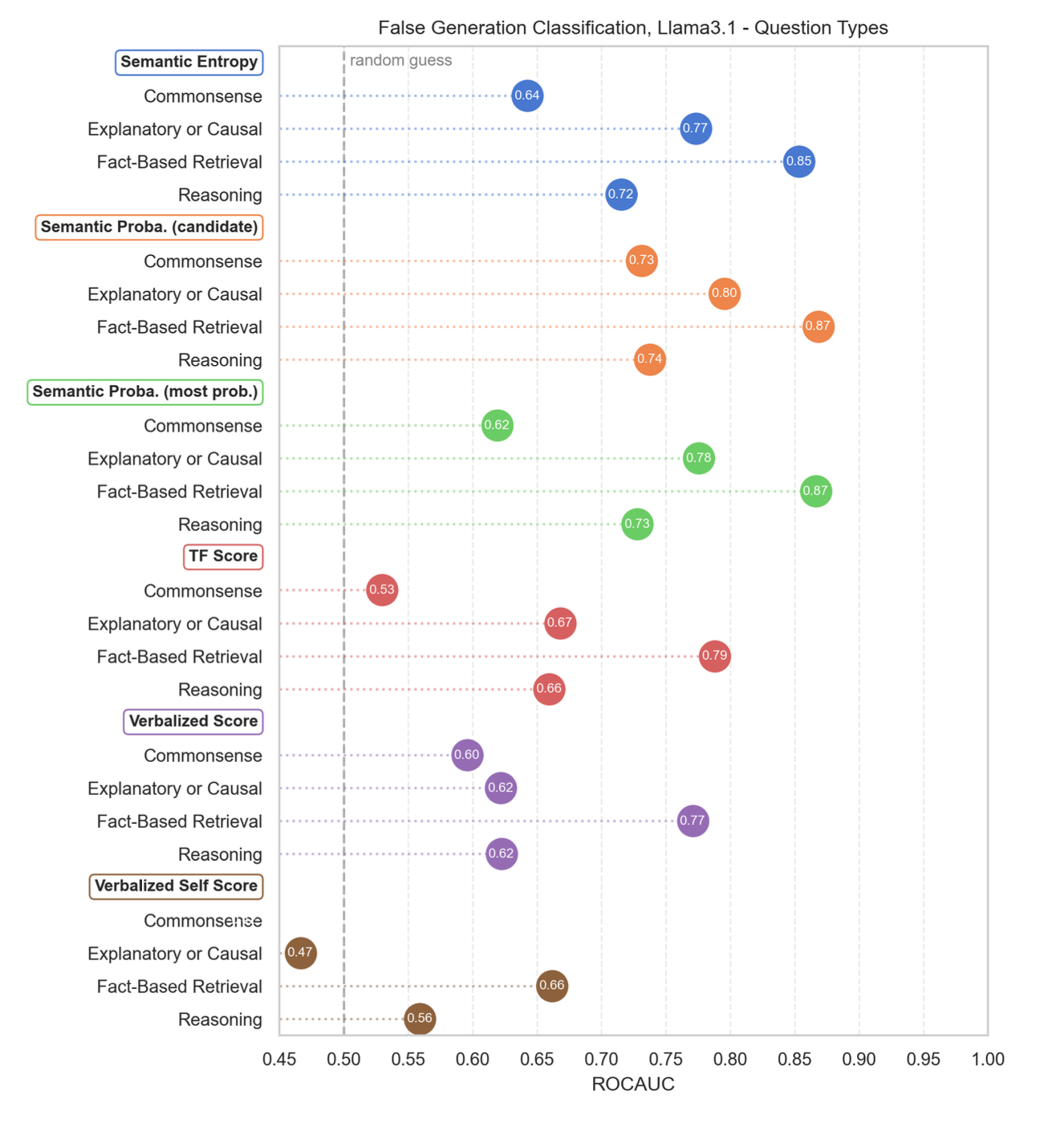
Our findings suggest:
- Domain Sensitivity: A method can excel in one domain yet fail in another. For instance, Gemma’s verbalized confidence proved to be reliable on history questions but degraded to near-random performance for ethics.
- Semantic Probabilities Perform Well: Approaches using semantic probabilities—where confidence is inferred from the frequency or entropy of multiple generated answers—tended to perform robustly across all categories. This supports earlier evidence that aggregating multiple samples can yield more stable and accurate UQ scores (Farquhar et al. 2024).
- Strongest Results on Fact-Retrieval: All UQ methods, including verbalized confidence, worked best for straightforward fact-retrieval questions (e.g., sports trivia, basic historical facts).
- Verbalized Confidence Limitations: For questions requiering deeper reasoning (e.g., multi-step or causal explanations), verbalized confidence often yielded near random performance. On the other hand, semantic probability approaches retained moderate effectiveness, suggesting that repeated sampling, or generally test-time compute, can capture uncertainty better than a single, direct report from the model.
- Commonsense Challenges: In questions covering ethics or broad commonsense scenarios, all methods struggled. We hypothesize that the model’s internal “worldview,” fuzzy ground-truth labels, and limited understanding of complex human dynamics may lead to both over- and under-confidence in this domain.
Because of an exploratory nature of our work, these findings cannot be treated as definitive and generalizable facts but rather as observations of models behavior.
Semantic Multicalibration - Calibration Error Across Domains and UQ Methods (February 2025)
Prior studies (e.g., Detommaso et al. 2024) highlight that calibration errors can vary significantly across domains—a phenomenon sometimes referred to as multicalibration. We hypothesize that the same occurs across different notions of uncertainty. To investigate this, we computed the Average Squared Calibration Error (ASCE) for various UQ approaches and compared them to ground-truth correctness labels. Our results confirm that models are not uniformly calibrated across domains or question types.
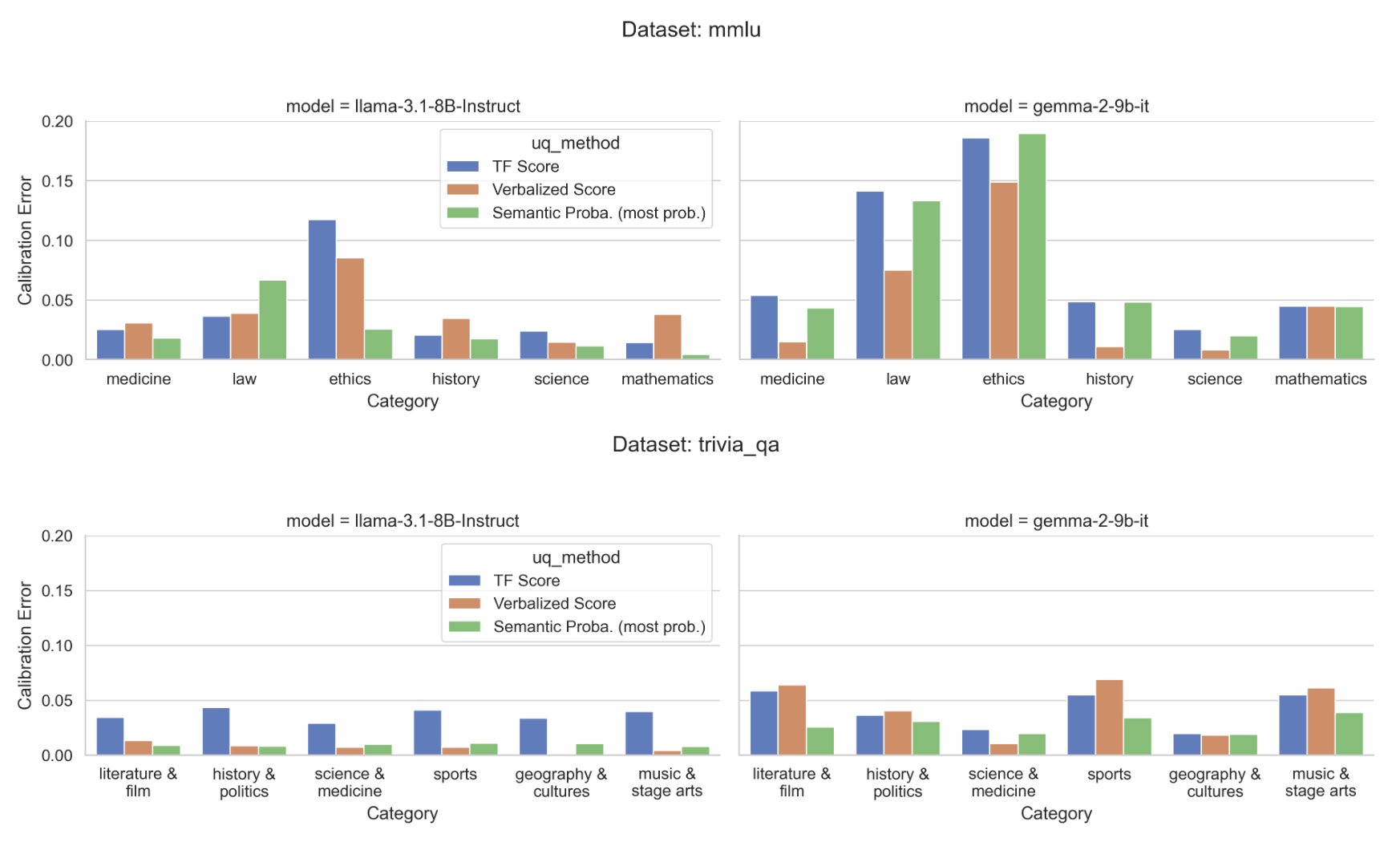
For example, in TriviaQA with the Llama model, the ethics category exhibits high calibration error when using verbalized confidence but lower error for semantic probabilities. In contrast, the law category shows the opposite pattern. This discrepancy underscores how calibration in one domain or definition of uncertainty does not necessarily translate to accurate calibration in another. This emphasizes the importance of domain and task-specific UQ strategies.
Verbalized Score Effectiveness vs Model’s Correctness (March 2025)
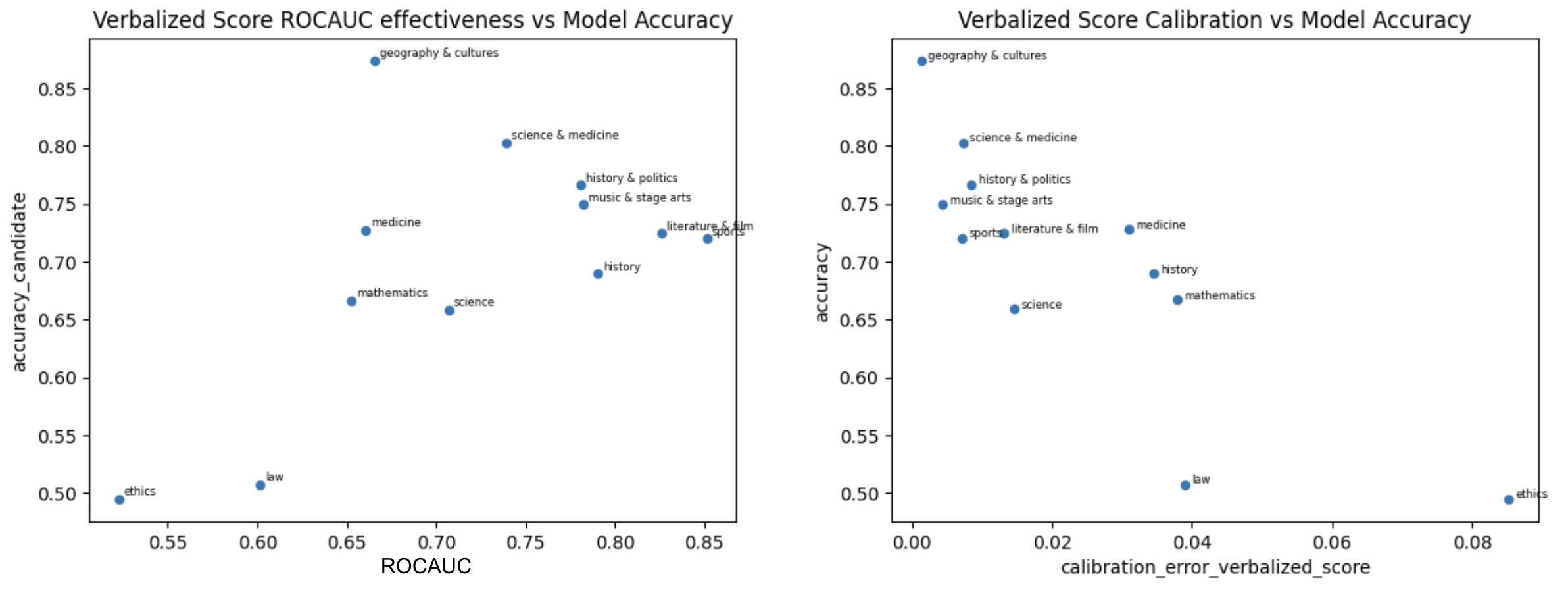
We observe that verbalized confidence performs best on easier domains, that is ones with higher correctness of answers. For such domains the calibration errors tend to be lower as well. These domains - often sports, literature, history, science - feature straightforward, fact-based questions with minimal ambiguity. Consistent with our earlier observations, such fact-retrieval tasks lend themselves to more accurate self-reported confidence.
Longer Reasoning vs Verbalized Score Effectiveness (March & April 2025)
In earlier work, Jurayj et al. 2025 showed that extended reasoning budgets can improve overall question-answering performance in selective QA contexts - though that study primarily used token-level confidence for mathematical questions. Here, our focus is on how additional reasoning specifically influences verbalized confidence. We want to find out whether producing more detailed or iterative answers (e.g., using Deepseek R1’s think-before-you-answer finetuning) with a forced budget (Muennighoff et al. 2025) makes the model overconfident, more consistent, or better calibrated than simpler approaches. Another question is whether domain-specific differences remain with larger test-time-compute budget.
We use our “SampleQA” dataset - 202 QA items drawn from TriviaQA, SimpleQA, GSM8k, AIME, and MMLU, and analyze how stated, verbalized confidence change with different numbers of reasoning tokens.
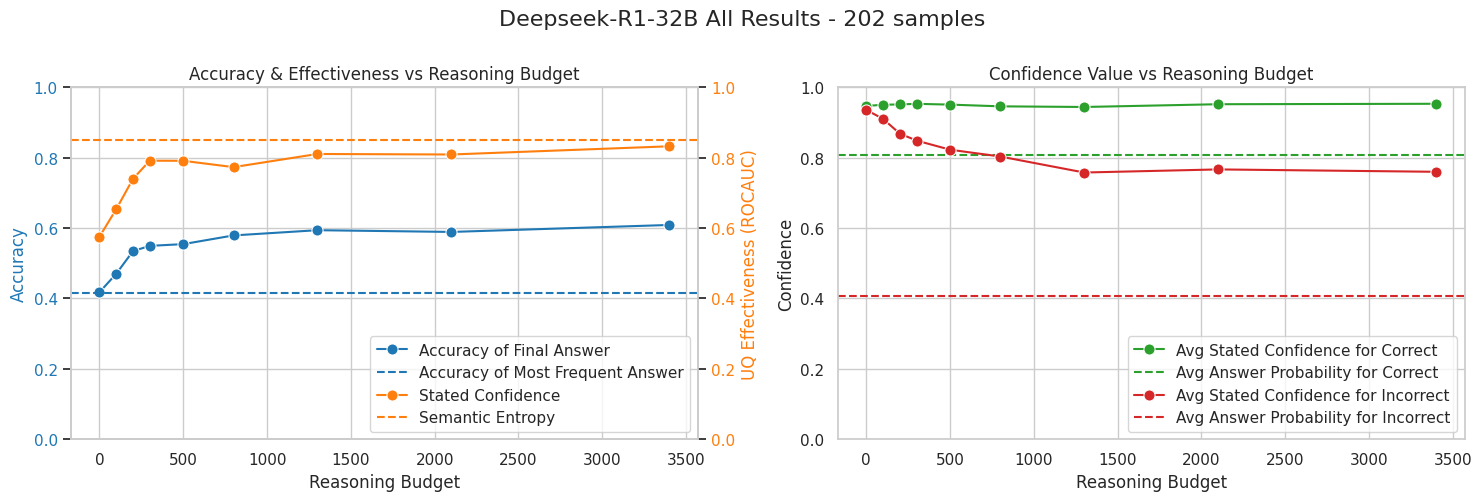
From these preliminary results, stated confidence for incorrect answers tends to decrease with increased reasoning, leading to a notable improvement in how well the stated confidence correlates with actual correctness. Over time, this improvement approaches roughly the same effectiveness level as Semantic Entropy, the multi-sample approach discussed earlier.
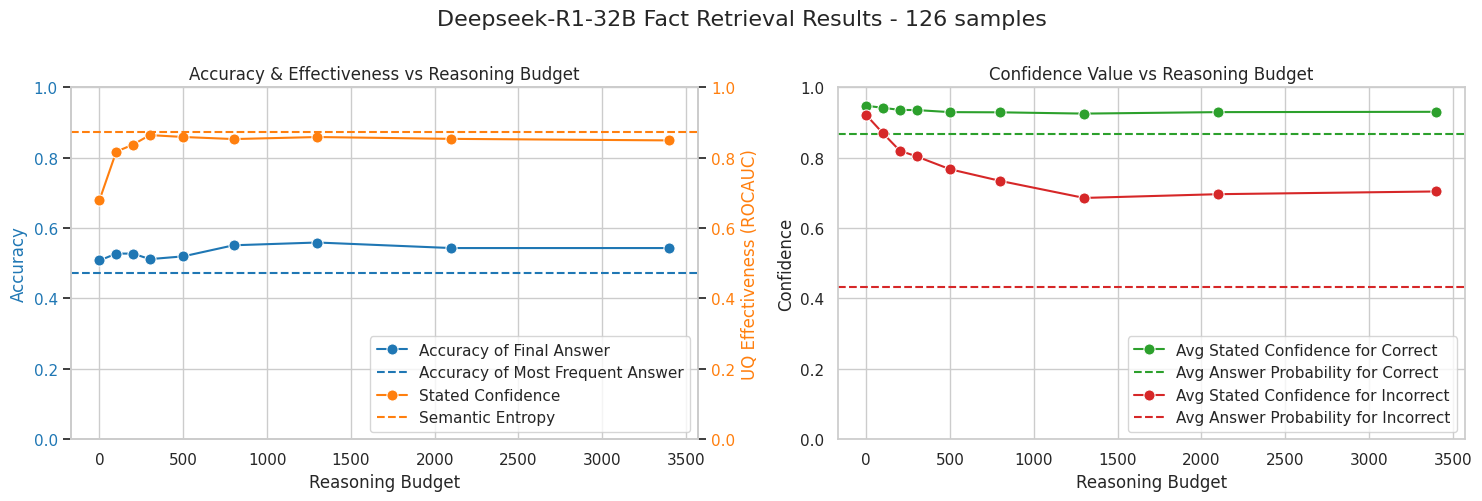
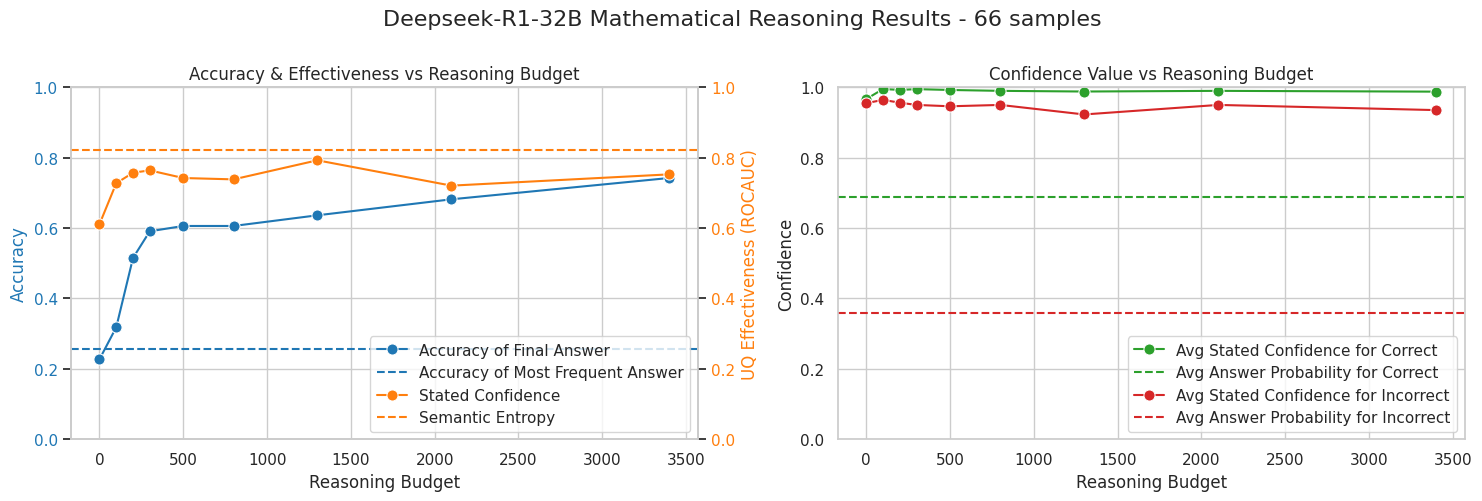
We see that extended reasoning does not always produce large accuracy gains, particularly for fact-retrieval tasks that rely on recalling a single fact rather than deriving one. Nevertheless, in simple fact-retrieval tasks higher reasoning budget still produces more accurate self-reported confidence. In mathematical reasoning, both accuracy and calibration improve more substantially, indicating that more complex tasks benefit from longer reasoning in multiple ways.
These observations support our idea that the model has no built-in sense of verbalized confidence and must instead discover uncertainty by exploring its answer space. This exploration can be done in two main ways:
- By sampling multiple responses (e.g., 10 or 100 times) and aggregating statistics (such as Semantic Entropy),
- By engaging in more reasoning time, so that when the model finally commits to an answer, it has examined a wider range of possibilities. We hypothesize that in this scenario, the final verbalized confidence is just a self-reported “statistic” describing the sampled tokens in the reasoning trace.
To further strengthen our hypothesis and the findings above, we propose additional small-scale experiments described in the next section.
Ablation studies and reasoning trace analysis (April 2025)
All of the experiments above are done on a SampleQA dataset with reasoning traces of length 1300 for the first two experiments, and no reasoning for the last one.
Verbalized Score as a Statistic of In-Reasoning Entropy
In this experiment, we count the distinct entities and the frequency of their mentions within the reasoning trace, then compute an entropy measure. Next, we calculate the Spearman correlation between this entropy value and the final verbalized score. If the correlation is high, it suggests that the verbalized score can be viewed as a statistic capturing the amount of variation within the reasoning process.
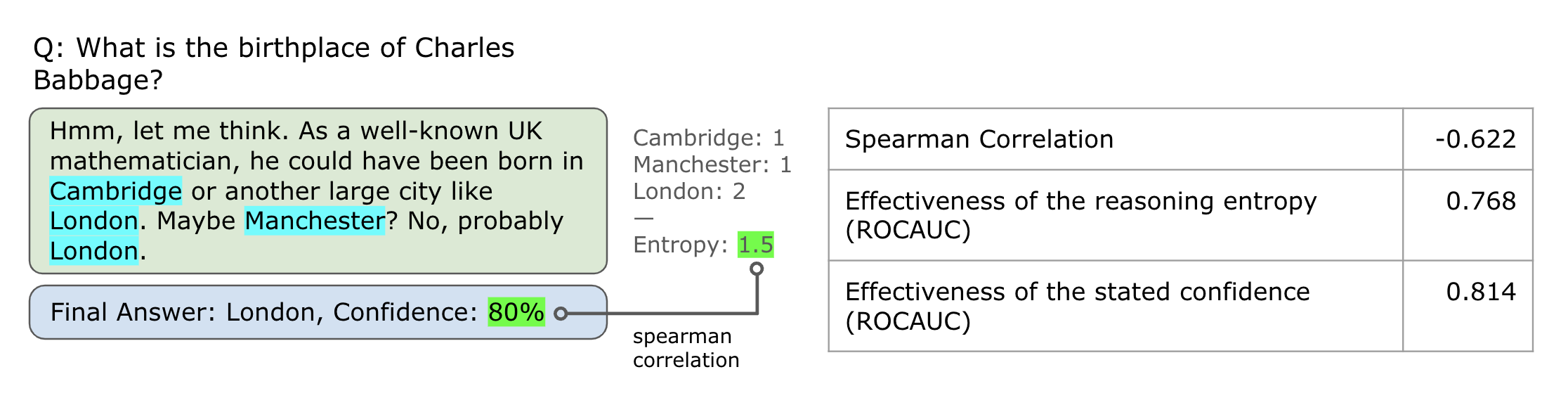
We see a moderate-strong correlation between two numbers, suggesting that there is some kind of connection between the two.
Modifying the Reasoning Trace to Include More Options
Here, we take an existing pair (reasoning, final answer) and use a different LLM to produce a modified reasoning that explicitly explores additional possibilities (e.g., “Option A, maybe B, or perhaps C”). We then ask Deepseek R1 to generate a new final answer as though this updated, more uncertain reasoning were its own. If the final confidence changes substantially, it supports the idea that the verbalized score is largely determined by how many alternative pathways the reasoning has considered.
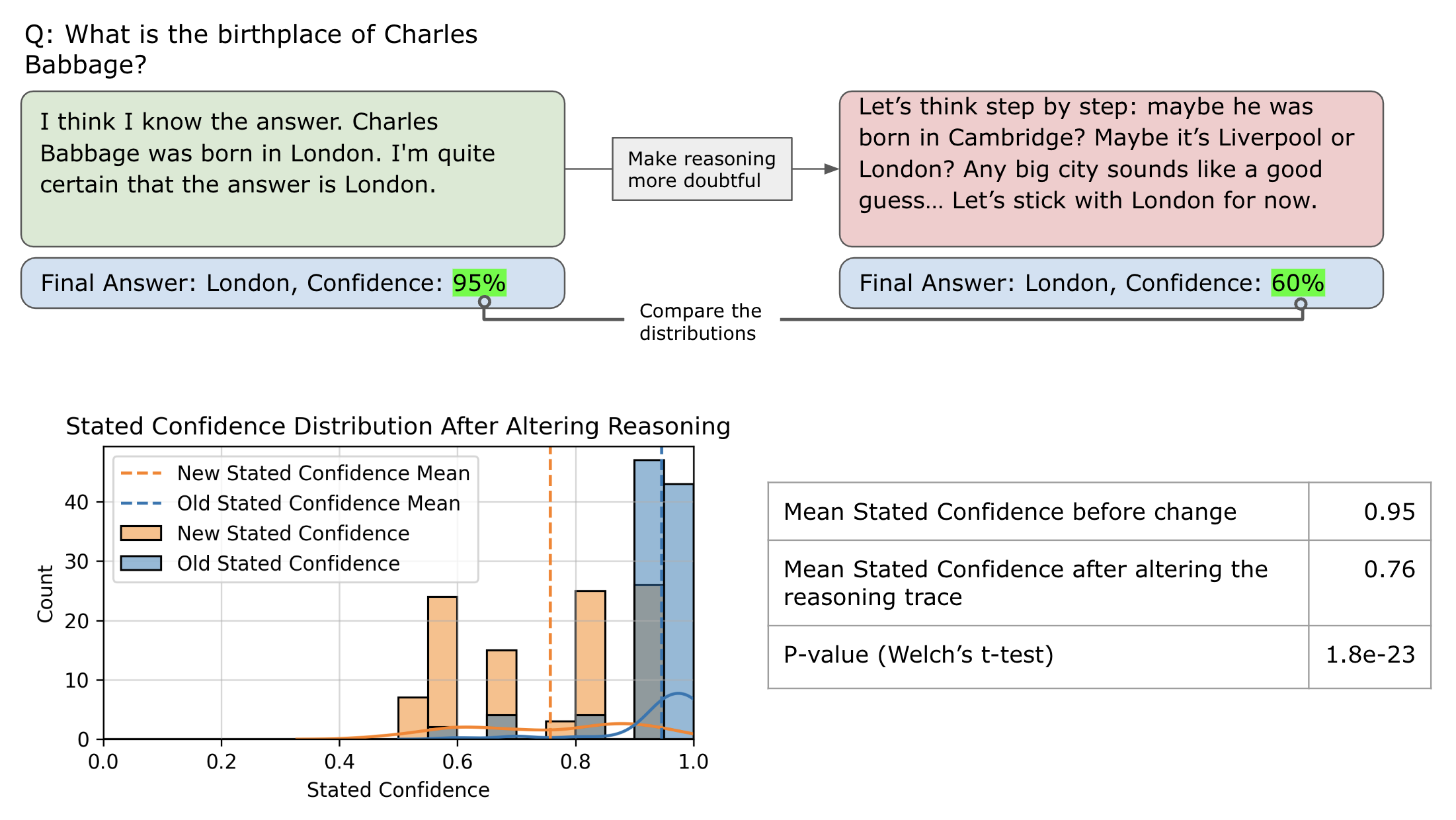
We see a very significant drop in the model confidence, it is a strong indicator that the verbalized score does not depend on the model intrinsic uncertainty, but rather on the generation space explored in the reasoning process.
Prompting the Model That a Question Is Difficult
We know the verbalized score can be influenced by prompt framing. For questions the model has already answered correctly in standard conditions, we add a note in the system prompt implying the question is hard, then observe how the final verbalized score shifts. If this change is large, it may indicate the model’s reported confidence stems more from a meta-level perception of difficulty than the actual reasoning steps. If the shift is smaller compared to the previous experiment, it suggests the verbalized score is more a reflection of the internally sampled possibilities rather than an uninformed sense of difficulty.
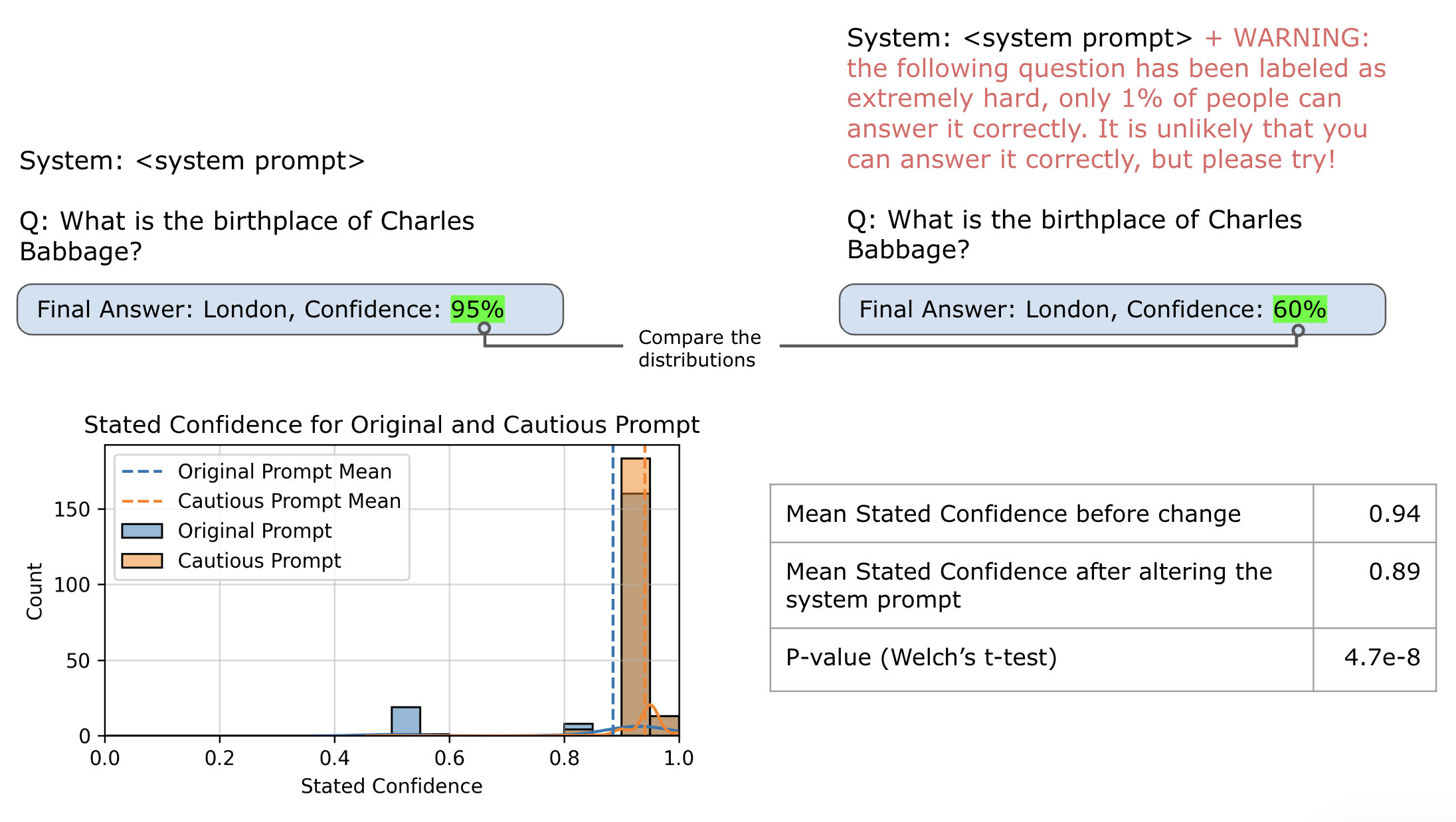
We see a lower drop in the model confidence than in the previous experiment. It is still significant statistically suggesting that the prompt framing is important, but the internal space explored by the model in the reasoning process is far more impactful.
Changelog:
- 19.03.2025: Added introduction, motivation, descriptions of existing methods and research questions
- 24.03.2025: Fixed the references links, backfilled experiments from Feb and early March, added planned experiments
- 08.04.2025: Added section about longer reasoning vs verbalized score effectiveness. Added 3 smaller experiments.